Overview
All coherence-related activity is broadcasted to all cache controllers in the system
The caches are all accessible via broadcast interconnect (e.g., bus or network), and all cache controllers monitor or snoop the interconnect to determine whether or not they have a copy of a block that is requested
Because the interconnect is shared, only one CPU can acquire medium access and have exclusive access for writing at a time. Medium arbitration and acquisition enforce write serialization
Broadcasting makes snooping easy to implement but limits scalability because every message may be broadcasted to all devices through the same medium. The medium becomes a bottleneck
Here we assume the following simplifications:
- Bus transactions are atomic: only one transaction is in progress on the bus at a time
- Memory operations are atomic: the CPU waits until its previous memory operation is complete before issuing another memory operation
- Transitions between states (stable states) are atomic
In reality, these simplifications are not true. See Snoop-Based Multiprocessor Design for implementation details
MSI
MSI is write-back, write-invalidate, snooping coherency protocol
- Modified/Exclusive (M): exclusive read/write access, dirty
- Shared (S): shared read access, clean
- Invalid (I): line is invalid
FSM for MSI (here “exclusive” means “modified”):
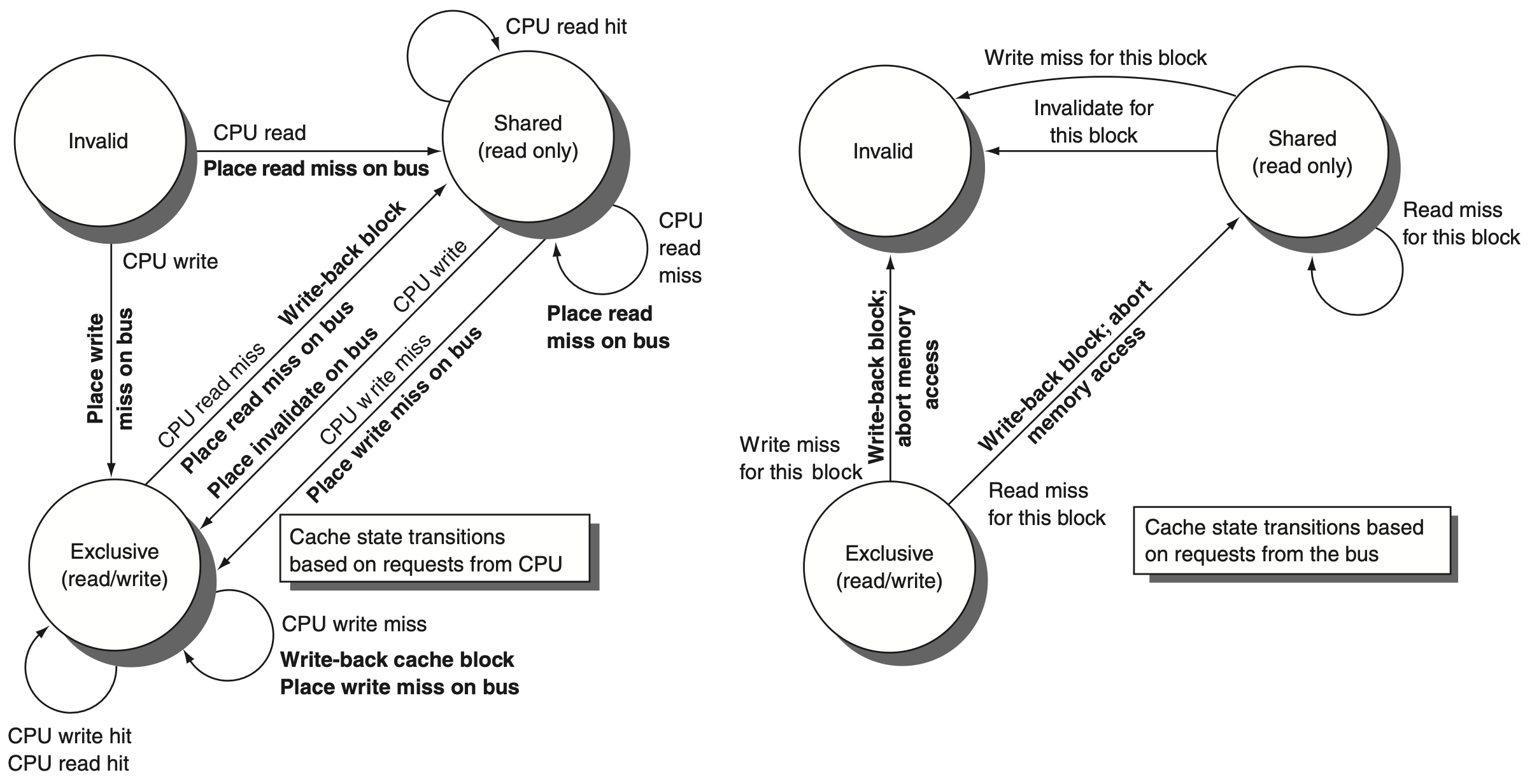
In contrast to SI write-through protocol, a line is flushed to memory only on eviction (write-miss, read-miss) and snooped write-miss and read-miss
Satisfying Coherency
MSI satisfies coherency conditions:
- “Program order” is implicitly satisfied by uniprocessor
- “Write propagation” is satisfied by the combination of invalidation and write-back actions
- “Write serialization” is satisfied:
- Writes that appear on interconnect are ordered by the order they appear on interconnect
- Reads that appear on interconnect are ordered by the order they appear on interconnect
- Writes that don’t appear on interconnect (write-back cache):
- Writes come between two interconnect transactions
- All writes are performed by the same CPU and ordered due to the 1st condition (“program order”)
- All other CPUs observe writes only after the interconnect transaction.
- So all CPUs see writes in the same order
MESI
Modified, Shared, and Invalid states same as in MSI
- Exclusive clean (E) state: exclusive read/write access, clean
MSI requires two interconnect transactions for the case of reading an address and then writing to it even if no sharing at all:
- Read miss on interconnect on CPU read to move from Invalid to Shared
- Invalidate on interconnect on CPU write to move from Shared to Modified (Exclusive)
In the uniprocessor scenario (no shared lines), only the first transaction is needed
With Exclusive clean state, MESI requires only one interconnect transaction to write to a line that is not shared:
- Read miss on interconnect on CPU read to move from Invalid to Exclusive clean if no sharing in other caches
- On CPU write, move from Shared to Modified (Exclusive)
Thus, the behavior is the same as in a uniprocessor scenario
For implementation details, see: Snoop-Based Multiprocessor Design.
MOESI
“Modified,” “Shared,” “Invalid,” “Exclusive clean” states same as in MESI
- Owned (O): shared read access, dirty
Allows sending dirty cache lines directly between caches instead of writing back to a shared lower cache (or memory) and then reading from there
References
- Cache coherence - Wikipedia
- Cache coherency protocols (examples) - Wikipedia
- Bus snooping - Wikipedia
- Directory-based cache coherence - Wikipedia
- False sharing - Wikipedia
- High Performance Computer Architecture: Part 5 - YouTube
- Computer Organization and Design RISC-V Edition The Hardware Software Interface (2nd ed). David A. Patterson, John L. Hennessy
- Snooping-Based Cache Coherence: CMU 15-418/618 Spring 2016
- Directory-Based Cache Coherence: CMU 15-418/618 Spring 2016
- A Basic Snooping-Based Multi-Processor Implementation: CMU 15-418/618 Spring 2016