Cache Hierarchy
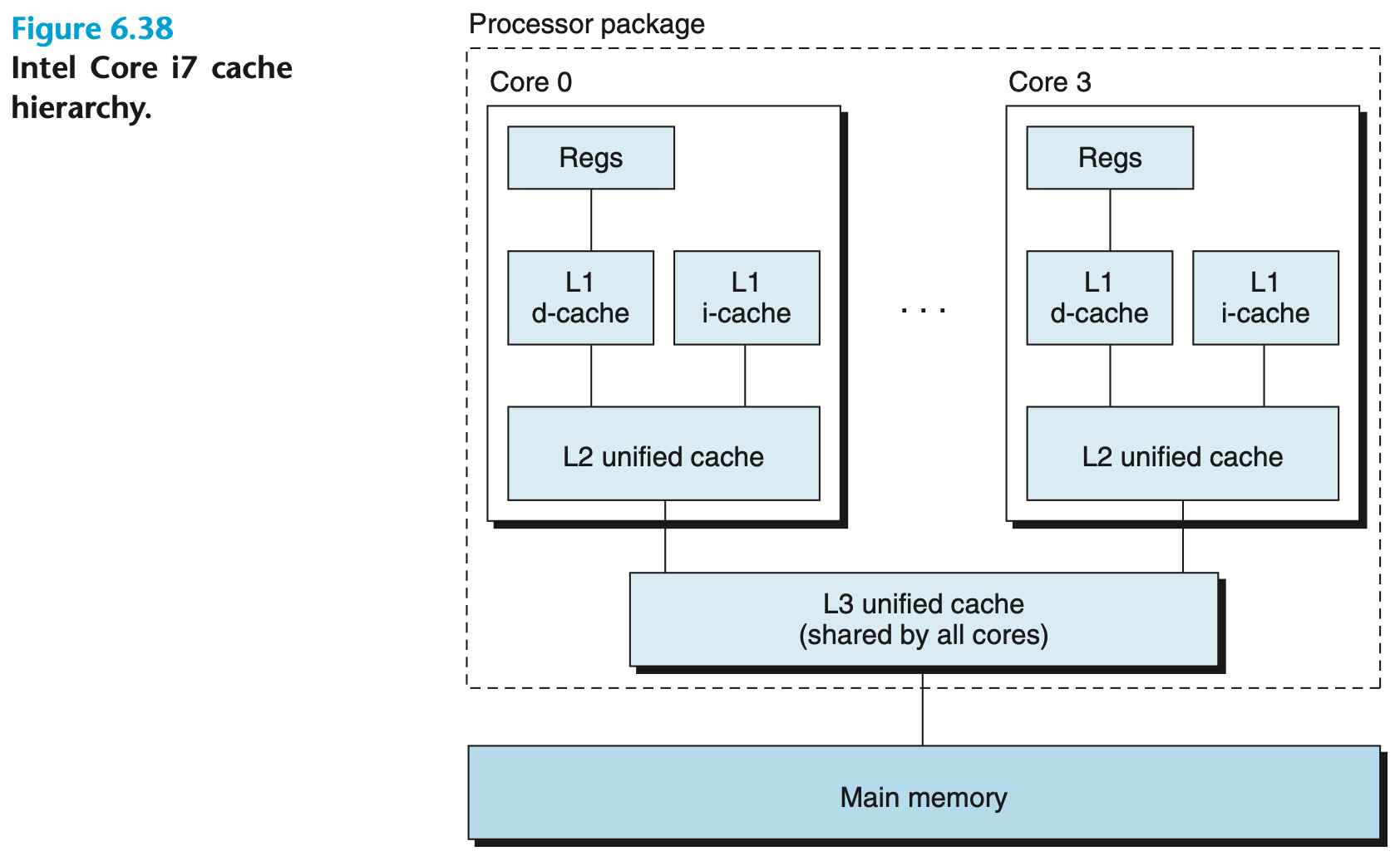
The L1 cache is usually split into two parts: the instruction cache (L1i) and the data cache (L1d). This division allows for a better utilization of locality since instructions and data are handled separately
Cache Memory Organization
Caches save a subset of data from a lower level
| Parameter | Description |
|---|---|
| Number of sets | |
| Number of set bits | |
| Number of cache lines per set | |
| Block size (bytes) | |
| Number of physical (main memory) address bits | |
| Number of block offset bits | |
| Number of tag bits | |
| Cache size (bytes), not including overhead such as the valid and tag bits |
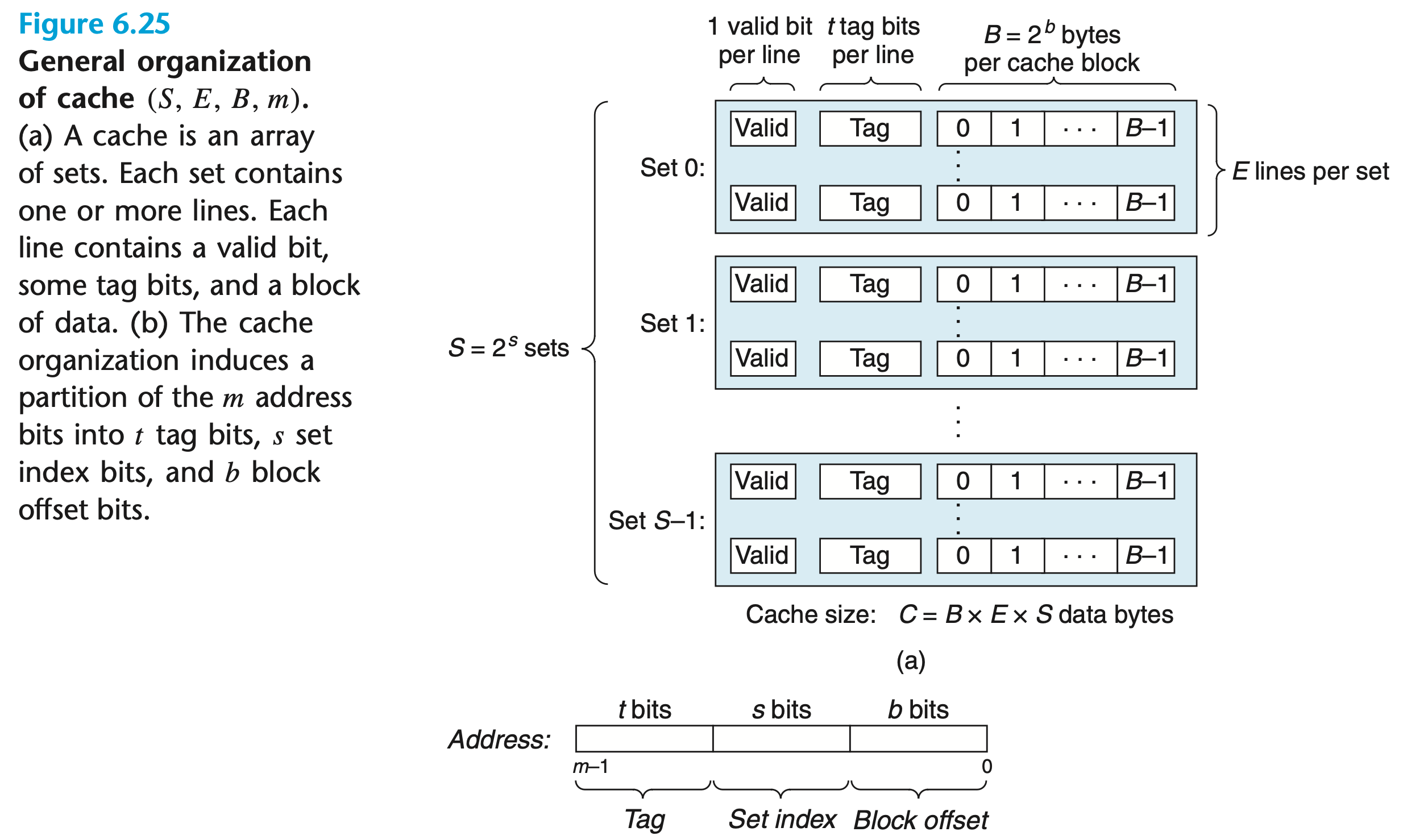
Middle bits are used for the set index because it allows contiguous blocks to be spread more evenly among cache sets. Indexing with the high-order bits would cause contiguous memory blocks to all map to the same cache set, leaving the rest of the cache unused
The cache stores and loads the whole cache data block (cache line) from/to lower levels
Cache Data Block Starting Address
Cache data blocks are -bytes aligned, for example, for a block of size =64 bytes the starting address can be 0, 64, 128, etc
Without this alignment requirement, set selection would be complex due to one cache data block spanning multiple set index bits. For example, if =8, =4, =1, and block spans addresses , then the block would occupy two set index bits: and TODO
Request Processing
Set Selection
Determine which set contains the requested word that we want to read or write (update)
Line Matching
Determine which cache line (if any) contains . If some cache line contains , we have a cache hit; otherwise, a cache miss
Line Replacement (Eviction)
On read misses and write misses in write-allocate caches, we need to retrieve the line containing the requested word from the next level in the memory hierarchy
If the set is full, we need to replace (evict) some line based on the replacement policy
Word Extraction
Cache data block size is larger than word size, so we need to determine where in a cache block the word is contained
Direct-Mapped Cache Request Processing
A cache with one cache line per set:
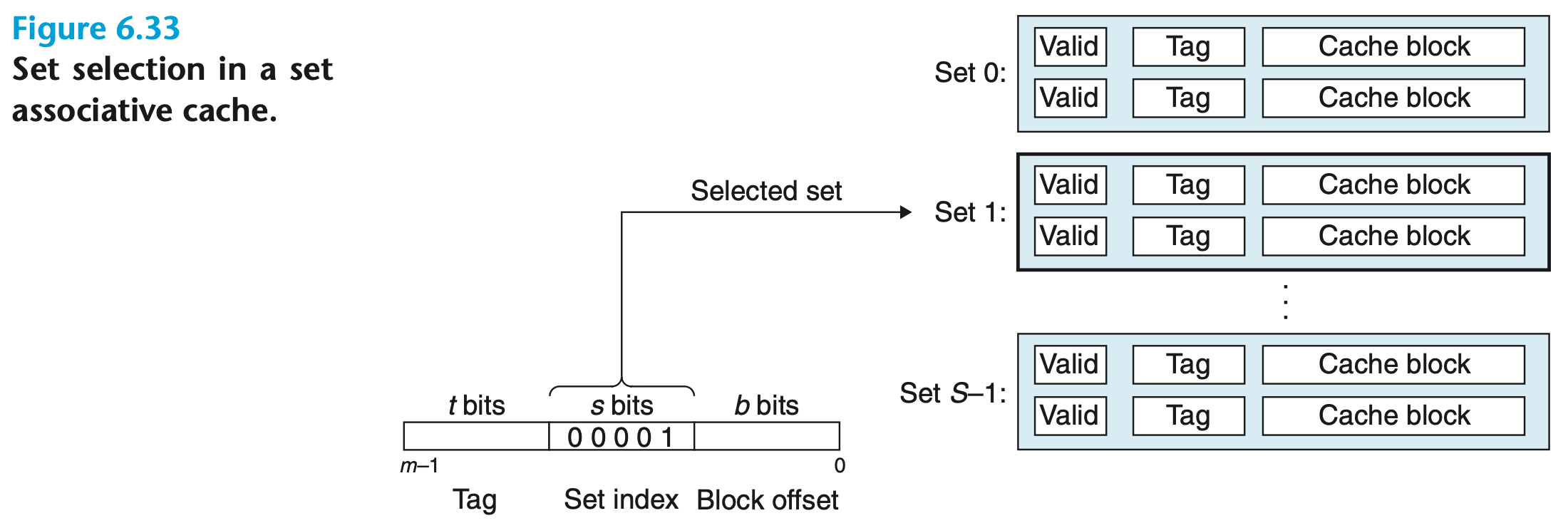
Set Selection
Set index bits in the address of are interpreted as an unsigned integer that corresponds to a set number
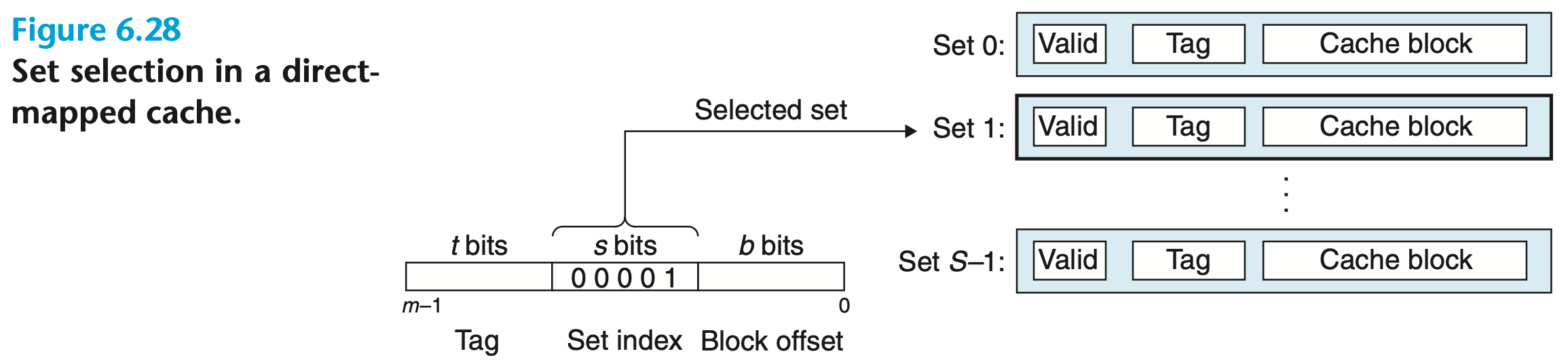
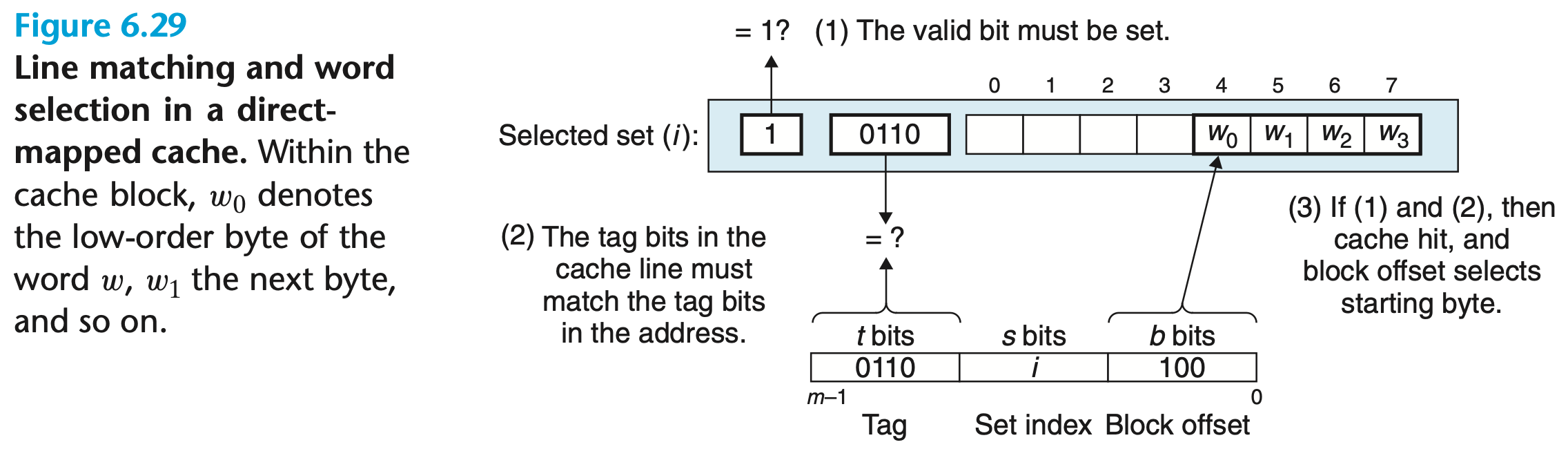
Line Matching and Word Extraction
The word is contained in the line if and only if the valid bit is set, and the tag bits in the cache line match the tag bits in the address of
Block offset bits in the address of determine the offset of the first byte in the word
Line Replacement
There is only one cache line per set, so the current line is replaced by the newly fetched line
Set Associative Cache Request Processing
A cache with several cache lines per set:
Set Selection
Set index bits in the address of are interpreted as an unsigned integer that corresponds to a set number
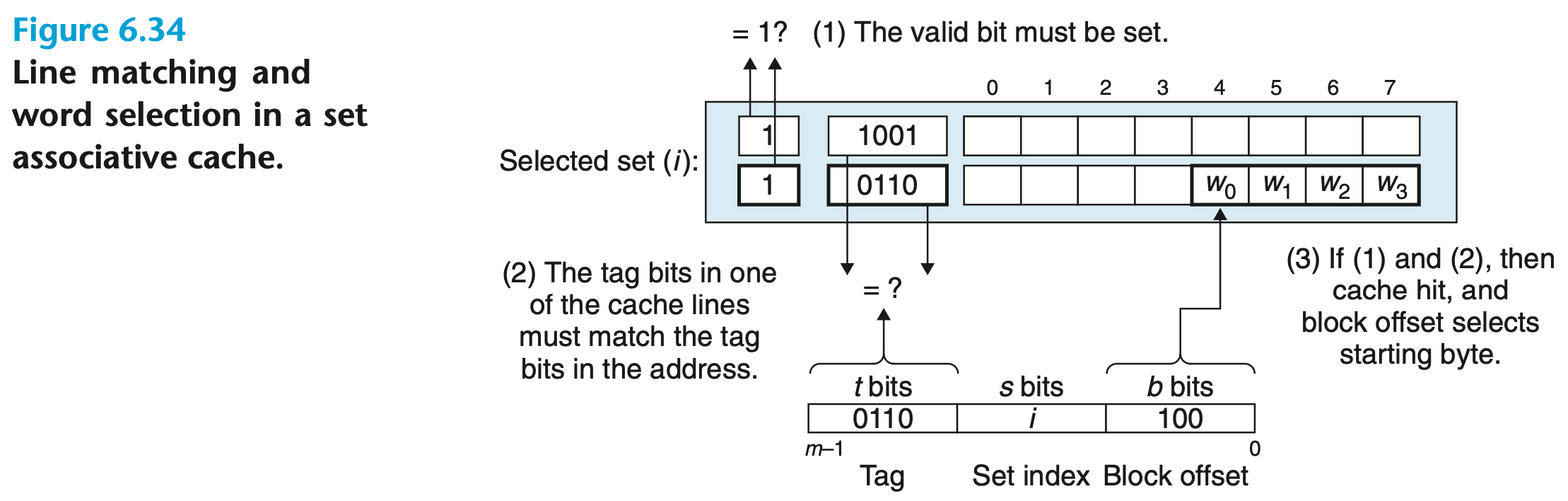
Line Matching and Word Extraction
The word is contained in the line if and only if the valid bit is set, and the tag bits in the cache line match the tag bits in the address of
Because there are multiple lines in the set, check each line in parallel. Circuitry becomes more complex
Block offset bits in the address of determine the offset of the first byte in the word
Line Replacement
The line to be replaced is chosen by the replacement policy (LRU, LFU) among the lines in the set. Need to store additional information to support replacement: access counters, age bits, etc.
Fully Associative Cache Request Processing
A cache with one set containing all cache lines:
Set Selection
There is only one set and no set bits in the address of , so it is always selected

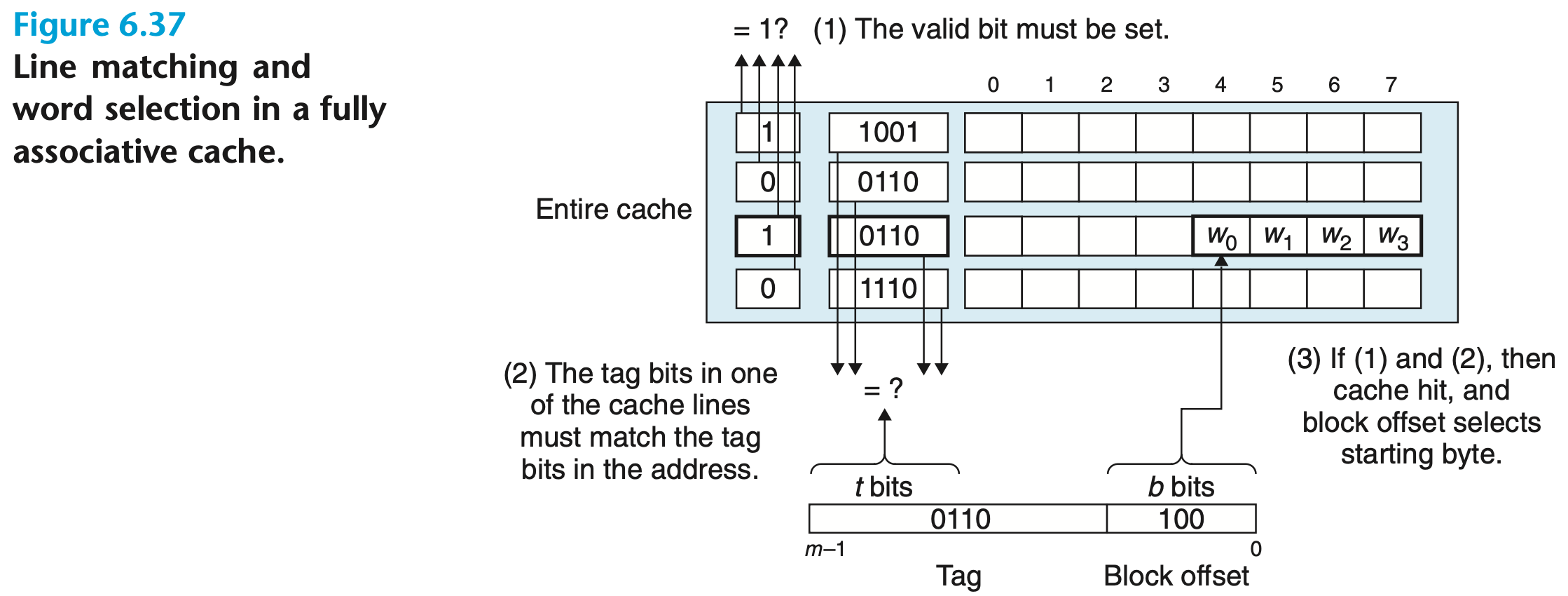
Line Matching and Word Extraction
The word is contained in the line if and only if the valid bit is set, and the tag bits in the cache line match the tag bits in the address of
We need to check all cache lines in parallel. Circuitry becomes very complex
Block offset bits in the address of determine the offset of the first byte in the word
Line Replacement
The line to be replaced is chosen by the replacement policy (LRU, LFU) among all the lines. Need to store additional information to support replacement: access counters, age bits, etc.
Write-Hit Policies
When we write the word to the cache that already has its copy cached (write hit), we must update the copy of the data in the next lower level of the memory hierarchy
Write-Through
Write is done synchronously both to the cache and to the next lower level
Inefficient because of a very high bandwidth requirement
Write-Back
Write is initially done only to the cache. Write to the next lower level is postponed for as long as possible and done only when the line is evicted from the cache by the replacement algorithm
The cache maintains a dirty bit for each cache line that indicates whether or not it has been modified
Write Buffer
A write miss in a write-back cache can involve two bus transactions:
- Incoming line - the line requested by the CPU
- Outgoing line - evicted dirty line that must be flushed
Ideally, we would like the CPU to continue as soon as possible without waiting for the flush to the lower level
The solution is a write buffer:
- Save the line to be flushed in a write buffer
- Immediately load the requested line, which allows the CPU to continue
- Flush the write-back buffer at a later time
Write-Miss Policies
When we write the word to the cache that doesn’t have it cached (write miss), we must decide whether to load the data to the cache since no data is returned on write operations
Write Allocate
Data at the missed-write location is loaded into the cache, followed by a write-hit operation
In this approach, write misses are similar to read misses
No-Write Allocate
Data at the missed-write location is not loaded into the cache and is written directly to the next lower level
In this approach, data is loaded into the cache on read misses only
Cache Inclusion Policy
Inclusive
A lower-level cache is inclusive of a higher-level cache if it contains all entries present in a higher-level cache
- If the block is found in L1, it’s returned to the CPU
- If the block is not found in L1 but found in L2, it’s returned to the CPU and placed in L1
- If the block is not found in L1 and L2, it’s fetched from memory and placed in both L1 and L2
- Eviction from L1 doesn’t involve L2
- Eviction from L2 is propagated to L1 if the evicted block also exists in L1
Exclusive
A lower-level cache is exclusive of a higher-level cache if it contains only entries not present in a higher-level cache
- If the block is found in L1, it’s returned to the CPU
- If the block is not found in L1 but found in L2, it’s moved from L2 to L1
- If the block is not found in L1 and L2, it’s fetched from memory and placed in L1 only
- A block evicted from L1 is placed into L2. It’s the only way L2 gets populated
- Eviction from L2 doesn’t involve L1
NINE
A lower-level cache is non-inclusive non-exclusive if it’s neither strictly inclusive nor exclusive
- If the block is found in L1, it’s returned to the CPU
- If the block is not found in L1 but found in L2, it’s returned to the CPU and placed in L1
- If the block is not found in L1 and L2, it’s fetched from memory and placed in both L1 and L2
- Eviction from L1 doesn’t involve L2
- Eviction from L2 doesn’t involve L1
Addressing
Instructions use virtual addresses, caches can use virtual or physical addresses for the index and tag
Physically Indexed, Physically Tagged (PIPT)
Use the physical address for both the index and the tag
Simple but slow because the need to translate to a virtual address, which may involve a TLB miss and RAM access
Virtually Indexed, Virtually Tagged (VIVT)
Use the virtual address for both the index and the tag
Fast because MMU is not used to translate to a physical address
Complex design:
- Different virtual addresses can refer to the same physical address (aliasing), which can cause coherency problems
- The same virtual address can map to different physical addresses (homonyms)
- Mapping can change, requiring cache flushing
Virtually Indexed, Physically Tagged (VIPT)
Use the virtual address for the index and the physical address in the tag
The advantage over PIPT is lower latency, as the cache line can be looked up in parallel with the TLB translation, but the tag cannot be compared until the physical address is available
The advantage over VIVT is that since the tag has the physical address, the cache can detect homonyms
Physically Indexed, Virtually Tagged (PIVT)
Useless and not used in practice
Types of Misses
Compulsory (Cold) Miss
The very first access to a block cannot be in the cache, so the block must be brought into the cache
Capacity Miss
If the cache cannot contain all the blocks needed during the execution of a program, capacity misses (in addition to compulsory misses) will occur because of blocks being discarded and later retrieved
Conflict Miss
If the block placement strategy is not fully associative, conflict misses (in addition to compulsory and capacity misses) will occur because a block may be discarded and later retrieved if multiple blocks map to its set and accesses to the different blocks are intermingled
Coherency Miss
Misses due to invalidations when using invalidation cache coherency protocol
Cache Coloring
Cache coloring - WikipediaTODO
Prefetching
A technique used by CPU to boost execution performance by fetching instructions or data into caches before it is actually needed
Cache prefetching can be accomplished either by hardware or by software:
- Hardware based prefetching is accomplished by having a prefetcher in the CPU that watches the stream of instructions or data, recognizes the next few elements that the program might need based on this stream and prefetches into the cache
- Software based prefetching is accomplished by inserting prefetch instructions in the program during compilation. For example, intrinsic function
__builtin_prefetchin GCCoco
References
- Computer Systems A Programmer’s Perspective, Global Edition (3rd ed). Randal E. Bryant, David R. O’Hallaron
- Dive Into Systems A Gentle Introduction to Computer Systems. Suzanne J. Matthews, Tia Newhall, Kevin C. Webb
- What every programmer should know about memory
- Cache replacement policies - Wikipedia
- Cache (computing) - Wikipedia
- Cache inclusion policy - Wikipedia
- CPU cache - Wikipedia
- Snooping-Based Cache Coherence: CMU 15-418/618 Spring 2016
- Directory-Based Cache Coherence: CMU 15-418/618 Spring 2016
- A Basic Snooping-Based Multi-Processor Implementation: CMU 15-418/618 Spring 2016
- High Performance Computer Architecture: Part 3 - YouTube
- High Performance Computer Architecture: Part 4 - YouTube
- Cache prefetching - Wikipedia
- Cache Block Start Addr - Georgia Tech - HPCA: Part 3 - YouTube