Internals
The runtime.g Struct
type g struct {
// Stack describes the actual stack memory: [stack.lo, stack.hi).
stack stack
// stackguard0 is the stack pointer compared in the Go stack growth prologue.
// It is stack.lo+StackGuard normally, but can be StackPreempt to trigger a preemption.
stackguard0 uintptr
// stackguard1 is the stack pointer compared in the //go:systemstack stack growth prologue.
// It is stack.lo+StackGuard on g0 and gsignal stacks.
// It is ~0 on other goroutine stacks, to trigger a call to morestackc (and crash).
stackguard1 uintptr
m *m // current m
gopc uintptr // pc of go statement that created this goroutine
startpc uintptr // pc of goroutine function to execute
...
}
// Stack describes a Go execution stack.
// The bounds of the stack are exactly [lo, hi), with no implicit data structures on either side.
type stack struct {
lo uintptr
hi uintptr
}Represents a goroutine. When a goroutine exits, its g object is returned to a pool of free gs and can later be reused for some other goroutine. It contains the fields necessary to keep track of its stack and current status. It also contains reference to the code that it is responsible for running
The runtime.m Struct
type m struct {
g0 *g // goroutine with scheduling stack
gsignal *g // signal-handling g
goSigStack gsignalStack // Go-allocated signal handling stack
spinning bool // m is out of work and is actively looking for work
curg *g // current running goroutine
p puintptr // attached p for executing go code (nil if not executing go code)
nextp puintptr
oldp puintptr // the p that was attached before executing a syscall
...
}Represents an OS thread (machine). It has pointers to fields such as the g that it is currently running and associated p
When m executes code, it has an associated p. When m is idle or in a system call, it does not need a p
Spinning
The runtime.p Struct
type p struct {
m muintptr // back-link to associated m (nil if idle)
mcache *mcache // cache for small objects
pcache pageCache // cache of pages the allocator can allocate from without a lock
// Local runnable queue of goroutines. Accessed without lock.
runqhead uint32
runqtail uint32
runq [256]guintptr
// A runnable G that was ready'd by the current G and should be run next instead of what's in
// runq if there's time remaining in the running G's time slice.
// It will inherit the time left in the current time slice.
runnext guintptr
// Cache of mspan objects from the heap.
mspancache struct {
len int
buf [128]*mspan
}
// Cache of a single pinner object to reduce allocations from repeated pinner creation.
pinnerCache *pinner
// Timer heap.
timers timers
...
}
// Per-thread (in Go, per-P) cache for small objects.
// This includes a small object cache and local allocation stats.
type mcache struct {
_ sys.NotInHeap
nextSample uintptr // trigger heap sample after allocating this many bytes
scanAlloc uintptr // bytes of scannable heap allocated
// Allocator cache for tiny objects w/o pointers.
tiny uintptr
tinyoffset uintptr
tinyAllocs uintptr
alloc [numSpanClasses]*mspan // spans to allocate from, indexed by spanClass
stackcache [_NumStackOrders]stackfreelist // small stach cache
flushGen atomic.Uint32
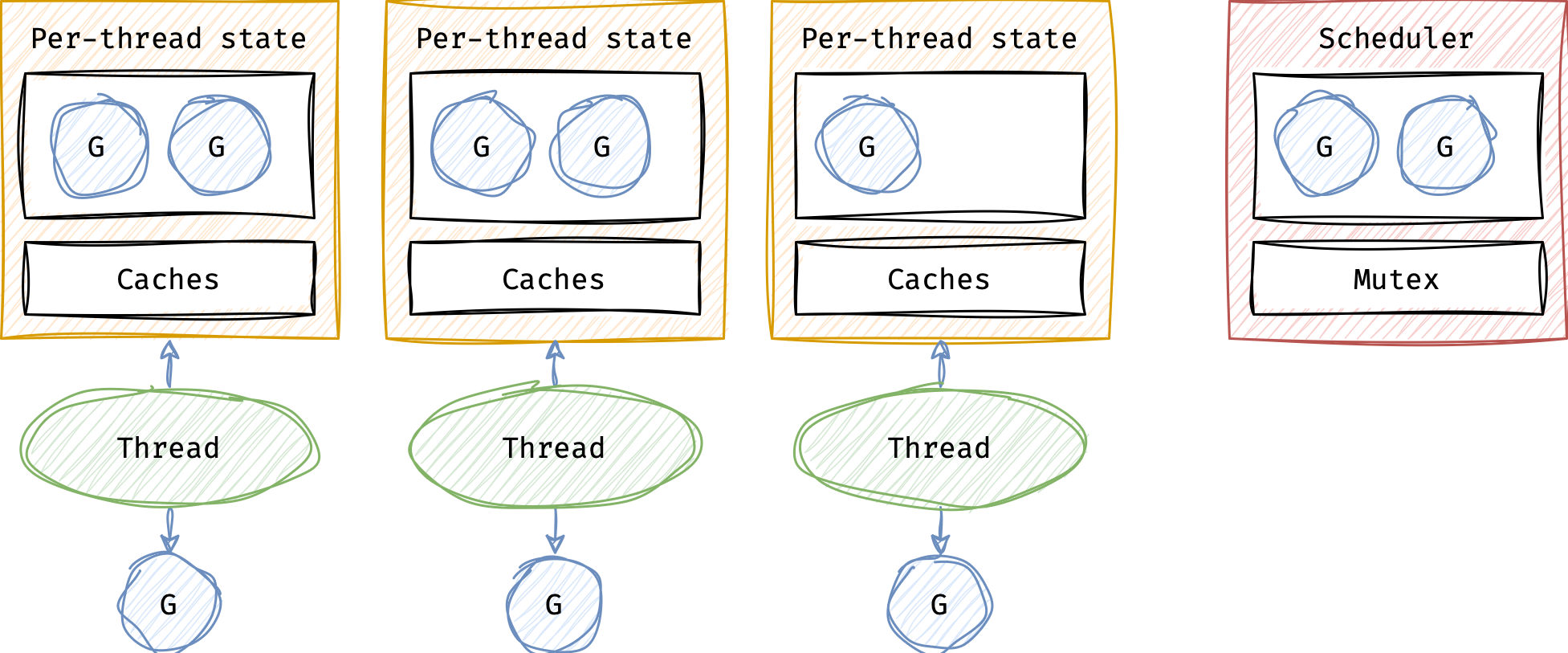
}Represents a processor abstraction, resources required to execute a g. Contains a lock-free local run-queue p.runq and caches
There are exactly GOMAXPROCS ps, thus even if we had a lot of ms, there are no scalability issues with work stealing and per p caches accesses
The runtime.schedt Struct
type schedt struct {
lock mutex
midle muintptr // idle m's waiting for work
pidle puintptr // idle p's
nmspinning atomic.Int32
// Global runnable queue.
runq gQueue
runqsize int32
// Central cache of sudog structs.
sudoglock mutex
sudogcache *sudog
// sysmonlock protects sysmon's actions on the runtime.
sysmonlock mutex
}Represents a scheduler itself. Contains a global run-queue schedt.runq protected by a mutex schedt.lock
Scheduling Algorithm
Handoff and System Calls
If OS thread m itself is blocked, e.g. in a system call, the scheduler has to handoff p to other m in order to prevent CPU underutilization
However, not all system calls are blocking in practice, e.g. vDSO. Having goroutines go through the full work of releasing their current p and then re-acquiring one for these system calls has two problems:
- There’s a bunch of overhead involved in locking (and releasing) all of the data structures involved
- If there’s more runnable
gs thanps, agthat makes a syscall won’t be able to re-acquire apand will have to park itself; the moment it released thep, something else was scheduled onto it
So the scheduler has two ways of handling blocking system calls, a pessimistic way for system calls that are expected to be slow; an optimistic way for ones that are expected to be fast
The pessimistic system call path implements the approach where p is handed off m before the system call
The optimistic system call path doesn’t release the p; instead, it sets a special p state flag and just makes the system call. The sysmon goroutine periodically looks for ps that have been in this state for too long and hands them off m
When m returns from a syscall the scheduler will check if the old p is available. If it is, the m will associate itself with it. If it is not, m will associate itself with any idle p. And if there are no idle ps, g will be dissociated from m and added to the schedt.runq
Thread m itself becomes idle, so we won’t run more gs than our target parallelism level
Fairness
The scheduler uses following mechanisms to provide fairness at minimal cost. Fairness helps preventing goroutines livelocks and starvation
Goroutine Preemption
Scheduler uses a 10ms time slice after which it preempts the current goroutine, enqueues it to global schedt.runq and schedules another goroutine
To preempt a g, a scheduler spoofs gs stack limit by setting g.stackguard0 to stackPreempt which causes stack overflow in function prologue check code. At runtime (already in slow path) scheduler recognizes that actually there is enough stack and it was a preemption signal. This spoof technique is an optimization to reduce the overhead of checking the preemption status on each function invocation explicitly
todo this allows preemptable scheduler instead of cooperative scheduler used before, where gs could be preempted only in specific blocking cases (for example, channel send or receive, I/O, waiting to acquire a mutex)
Loop Preemption
Above approach doesn’t work for loops because, there are no function calls, hence no runtime.stachmap metadata needed for Go Garbage Collector
Go uses signal-based preemption with conservative innermost frame scanning to preempt tight loops:
- Send OS signal to preempt the goroutine
- Conservatively scan the function stack: assume that anything that looks like a pointer is a pointer. Only needed for innermost frame
- Precisely scan the rest of the stack
Local Run Queue Design
To fairly schedule gs we need FIFO, because LIFO would mean that two gs constantly respawning each other would starve other gs. We would always pop this two gs from the top never reaching the bottom
On the other hand, from CPU perspective we need LIFO, because it provides better cache locality. When g1 writes data to memory and then g2 resumes, using FIFO may result in g2 finding that the data is no longer in the cache, while LIFO ensures that data will still be in a cache
To provide this LIFO/FIFO behavior the scheduler saves a runnable g', that was ready’d by the current g and should be run next instead of what’s in p.runq, into the one element LIFO slot p.runnext. To ensure g' is not stolen by other m, goroutines from p.runnext are not allowed to be stolen for 3us
However, this p.runnext LIFO behavior can cause starvation. In this code, g1 and g2 always respawn each other in p.runnext never checking p.runq:
c1, c2 := make(chan int), make(chan int)
// g1
go func() {
for {
c1 <- 1
<-c2
}
}()
// g2
go func() {
for {
<-c1
c2 <- 2
}
}()To prevent p.runq starvation, g taken from p.runnext inherits current time slice and will be preempted within 10ms
Global Run Queue Polling
To avoid schedt.runq starvation, scheduler checks it every scheduling tick
Network Poller Async Notifications
To avoid network poller starvation, network poller uses background thread to epoll the network if it wasn’t polled by the main worker thread
Polling used for global run queue is not applicable here, because checking the network involves system calls like epoll which adds an overhead to the scheduler fast path
Goroutines Stack
todo See: I don’t know where goroutine stacks are allocated in virtual memory : r/golang
A traditional paging based stacks can’t be used:
- Not enough address space to support millions of 1Gb stacks. Because we need to reserve the virtual memory for all the stacks at the program startup, and we have 48 bits address space on 64 bit CPU, we can support only 128000 stacks
- Suboptimal granularity due to minimum page size of 4Kb
- Performance overhead due to system calls used to release unused pages
Instead, Go uses growable stacks allocated on the heap, which allows a goroutine to start with a single 2Kb stack which grows and shrinks as needed. A compiler inserts a prologue at the start of each function, which checks for the overflow by comparing the current stack pointer to g.stackguard0. When a stack overflow check triggers, runtime calls runtime⋅morestack to grow a stack:
- Allocate a new stack 2x the size of the old stack. This amortizes the cost of copying
- Copy the old stack to the new stack
- Adjust all pointers on the stack by utilizing
runtime.stackmapmetadata - Adjust all pointers into the stack from outside. There are a few despite escape analysis
- Deallocate the old stack
The p.mcache.stackcache is a cache of small stacks
References
- Source code: proc.go
- Source code: runtime2.go
- Source code: stack.go
- GopherCon 2018: Kavya Joshi - The Scheduler Saga - YouTube
- Dmitry Vyukov — Go scheduler: Implementing language with lightweight concurrency - YouTube
- runtime: tight loops should be preemptible · Issue #10958 · golang/go · GitHub
- dotGo 2017 - JBD - Go’s work stealing scheduler - YouTube
- Go’s work-stealing scheduler · rakyll.org
- Scheduling In Go : Part I - OS Scheduler
- The Golang Scheduler
- Внутреннее устройство планировщика Go // Демо-занятие курса «Golang Developer. Professional» - YouTube
- ТиПМС 9. Планировщик Go - YouTubetodo
- Contiguous Stacks Design Doc - Google Docstodo
- Go Preemptive Scheduler Design Doc - Google Docs
- Scalable Go Scheduler Design Doc - Google Docs
- HACKING.md
- GopherCon 2020: Austin Clements - Pardon the Interruption: Loop Preemption in Go 1.14 - YouTubeTODO
- Chris’s Wiki :: blog/programming/GoSchedulerAndSyscalls
- 100 Go Mistakes and How to Avoid Them. Teiva Harsanyi