Overview
This document explores techniques for implementing the basic snooping protocol using single-level and multi-level caches and shared atomic and non-atomic buses
Single-Level Cache with Atomic Bus
- A single level of a write-back cache per CPU
- Bus transactions are atomic, with only one transaction in progress at a time
- Operations within a process are atomic with respect to one another - the cache can stall the CPU while it performs the series of steps involved in a memory operation
Tag Design
Both requests from the bus and CPU require tags lookup, which can cause contention
We cannot prioritize the CPU or bus:
- If the bus receives priority: during bus transaction, the CPU is locked out from it’s own cache
- If the CPU receives priority: during CPU cache accesses, the cache can’t respond to snoop requests
We can resolve the issue by using duplicate tags and state for each block
Because tags must be in sync, tag update by one controller will still block another controller (but modifying tags is infrequent compared to checking them)
Another approach is dual-ported RAM for the state and tags
Reporting Snoop Results
MESI relies on information from other caches:
- If a line is in other CPUs caches, the line should transition to S state instead of E
- If a line is in M state in any cache, memory should not respond
Three additional bus OR-lines are added:
- Shared line - asserted when any of the CPU caches (excluding the requesting CPU) has a copy of the line
- Dirty line - asserted if any cache has the block in M state
- Inhibit line - asserted until all caches have completed their snoop; when deasserted, the snoop by all CPUs is complete, and CPU and RAM can examine shared line and dirty line
All the lines are essentially OR of results from all the CPUs
Dealing with Write Backs
A common optimization in a write-back cache is the use of a write-back buffer
Because data can be in a write-back buffer, the snoop controller (not the cache) must check the write-back buffer in addition to a cache
If there is a write-back buffer match:
- Respond with data from the buffer rather than the cache
- Cancel outstanding bus access request
Non-Atomic State Transitions
In cache coherency protocols, state transitions and their associated actions are assumed to be atomic
In reality, request processing takes multiple steps: looking up the cache tags, arbitrating for the bus, actions taken by other controllers at their caches, and the action taken by the issuing CPU at the end of the bus transaction
Although bus transactions are atomic, the set of actions as a whole is non-atomic
The cache must be able to handle requests while waiting to acquire the bus and be able to modify its own outstanding requests (e.g. replace invalidate request with write-miss request)
The solution is:
- Arbitrate for the bus first (before changing the cache state) and not release the bus until all actions are complete (snoop-pending line is 0)
- Add intermediate transient states to the protocol state diagram, for example: S→M, I→M, I→S,E, which allow revising (converting) requests and actions
Write Serialization
Because request processing takes multiple steps we need to define when the write is committed:
- The position of the write in the serial bus order is completely determined, regardless of further actions
- All future reads will return the new or later value (even if the value has not yet been written to the cache line or memory)
The write is committed when a read-exclusive (write-miss or invalidate) transaction is placed on the bus. The bus doesn’t wait for the transaction to reach the destination and return a reply
Thus, write serialization is defined by the order of transactions on the bus
The write is completed when the updated value is actually placed in each cache physical memory
The CPU can’t consider the write completed and complete other operations past it in program order until the write transaction appears on the bus and makes the write visible to other CPUs; otherwise, write serialization may be broken
Fetch Deadlock
A fetch deadlock is a deadlock that can occur in a two-phase protocol (e.g. request-response protocol)
In an SMP with an atomic bus, fetch deadlock can arise when the cache controller is awaiting the bus grant: it needs to continue performing snoops and handling requests, which may require it to flush blocks onto the bus
For example:
- Cache has a modified copy of a cache line
B - Cache is waiting for the bus access, so it can issue a write-miss transaction on a line
A - Read-miss transaction for a line
Bappears on the bus while cache is waiting
In this example (1) bus is held until a response to a read-miss occurs on the bus; (2) the cache is stalled sending write-miss until the bus is free. Thus, we have a deadlock
To eliminate deadlock, while an entity is attempting to issue it’s request, it needs to service incoming transactions
Cache must be able to service incoming requests while waiting to issue it’s own request
In our example, the cache must respond to a read-miss request (which does not require bus arbitration with an atomic bus) and change the state from modified to shared while it is waiting to acquire a bus
Livelock
Livelock can occur in an invalidation-based cache-coherent system if all CPUs attempt to write to the same memory location at about the same time
CPU write requires the following nonatomic set of events:
- Cache obtains exclusive ownership (write-miss) for the corresponding memory block (i.e., it invalidates other copies and obtains the block in the modified state)
- State machine in the CPU realizes that the block is now present in the cache in the appropriate state
- State machine reattempts the write
For example:
- Initially, no CPU has a copy of the location it its cache
- The block is brought into the cache in M state, but before the CPU is able to complete it’s write, the block is invalidated by a request from another CPU
- The CPU’s write attempt misses again, and the cycle can repeat indefinitely
To avoid livelock, a write that has obtained exclusive ownership (write-miss) must be allowed to complete before the exclusive ownership (write-miss) is taken away
Starvation
Starvation can occur if bus arbitration is not fair
Starvation can be avoided by using fair (e.g. FIFO) serve policies at the bus arbiter and elsewhere
Implementing Atomic Operations
“Parallel Computer Architecture A Hardware-Software Approach 6.2.9”TODO
Multi-Level Cache with Atomic Bus
A typical CPU has private L1 and L2 caches for each core and one shared L3 cache
Changes made to the L1 cache must be visible to the lower-level cache controller responsible for interconnect operations, and snooping interconnect transactions must be visible to the L1 cache
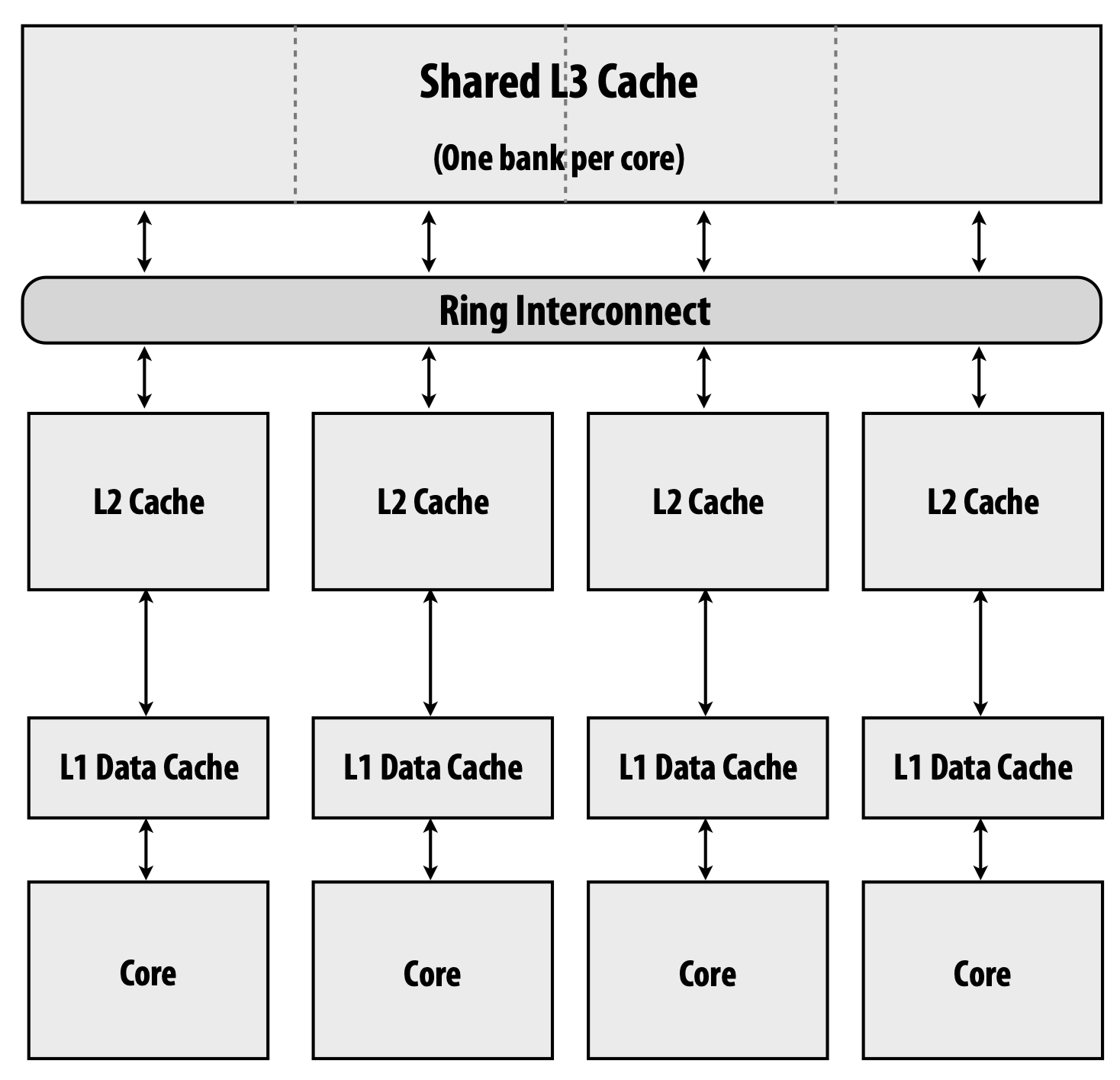
We can’t have independent snooping hardware for each level because it’s inefficient and causes high interconnect traffic
The solution is to ensure inclusion policy between caches:
- If a block is in L1, it must also be in L2. Contents of L1 are a subset of L2
- If a block is in a modified state (M in MESI, M,O in MOESI) in L1, it must also be in a modified state in L2
Inclusion Policy Violation
There are a couple of cache configurations that violate the inclusion policy
Set-Associative L1 Cache with History-Based Replacement Policy
Because the L1 cache is set-associative, it must use a replacement policy to choose which line to evict
The problem with history-based replacement policies (e.g., LRU) is that the L1 cache sees different access history from lower-level caches because all requests go to L1 but not all go to lower caches
Thus, the L1 cache and L2 cache can evict different lines, even if L2 is direct-mapped or set-associative as well
Multiple Caches at a Level
The L1 cache is often split into L1d and L1i caches. This can lead to inclusion violation
For example, an instruction block m1 and a data block m2 that conflict in the L2 cache do not conflict in the L1 caches since they go into different caches
If m2 resides in the L2 cache and m1 is referenced, m2 will be replaced from the L2, but not from the L1d, violating inclusion
Different Cache Block Sizes
If caches at different levels have different block sizes, they can violate the inclusion property
For example:
- Direct-mapped L1 cache with a 1-word block size and 4 sets
- Direct-mapped L2 cache with a 2-word block size and 8 sets
L1 can contain both words at location 0 and 17 (set 0 and 1), but L2 can’t because they map to the same set (set 0) and are not consecutive words. Thus, inclusion is violated
Maintaining Inclusion Policy
Inclusion is maintained explicitly by extending the mechanisms used for propagating coherence events in the cache hierarchies
Handling Bus Transaction
When a block in L2 is replaced, a request is sent to L1 to invalidate or flush (if dirty) the corresponding blocks (there can be multiple blocks if the L2 block size is bigger than L1)
Some transactions (not all) relevant to L2 are also relevant to L1 and must be propagated to it
The L2 cache could propagate every transaction to L1, but it’s inefficient and causes unnecessary intervention
The solution is to add an additional state bit for each L2 line indicating if the line also exists in L1
This bit tells L2 that a transaction for this line must be propagated to L1
Handling Writes
On an L1 write hit, the modification needs to be communicated to the L2 cache so it can supply the most recent data to the bus if necessary
We could make the L1 cache write-through, but it would consume L2 cache bandwidth, and we would also need a buffer between L1 and L2 to avoid CPU stalls
The solution for write-back L1 cache is to add an additional modified-by-stale state bit for each L2 line indicating if the line is dirty in L1
The block in the L2 cache behaves as a modified block for the coherence protocol, but data is fetched from the L1 cache when it needs to be flushed to the bus
Propagating Transactions for Coherence
CPU requests propagate downward until either they encounter a cache with a block in a proper state or they reach a bus.
Responses to CPU requests are sent up the cache hierarchy, updating each cache as they progress toward the CPU
Read responses are placed in each cache in shared or exclusive state
Write responses are placed in each cache except L1 in the modified-by-stale state and in L1 in the modified state.
Requests from the bus propagate upward from the bus, modifying the state of the cache blocks as they progress
Requests that require the line to be flushed (and possibly invalidated) propagate upward until they encounter a block in the modified state at which point a response to the bus is generated.
Tag Design
Dual tags are less critical in multilevel caches
The L2 cache acts as a filter for the L1 cache, screening out irrelevant transactions from the bus, so the tags of the L1 cache are available almost wholly to the CPU. Similarly, since the L1 cache acts as a filter for the L2 cache from the CPU side, the L2 tags are almost wholly available for the bus snooper’s requests
Nonetheless, many machines retain duplicate tags even in multilevel cache designs
Single-Level Cache with Split-Transaction Bus
Transaction processing on an atomic bus is inefficient because the bus is idle from the time when the address is taken by the bus until the memory system or another cache supplies the data or response
In a split-transaction bus, transactions that require a response are split into two independent sub-transactions: a request transaction and a response transaction
Other transactions (or sub-transactions) are allowed to intervene between them so that the bus can be used while the response to the original request is being generated
Bus Design
There can only be a limited number of outstanding requests on a bus at any given time
The split-transaction bus design essentially consists of two separate buses: a request bus for commands and addresses and a response bus for data
The request bus provides the type of request (read, write, read-miss, write-miss, etc.) and the target address
A response consists of data on the data bus and the original request tag on the tag lines
Responses may arrive out of order with regard to requests, so we need a way to match them with requests
The solution is to assign a unique tag to a request (command-address pair) when it is granted the bus by the arbiter
Request Table
Each controller maintains a fully associative request table to keep track of the outstanding requests on the bus
Whenever a new request is issued on the bus, it is added to all request tables at the same index
The index is a request tag assigned to the request
A request table entry contains the address of the block associated with the request, request type, state of the block in a local cache, and some miscellaneous information
All request table entries are examined for a match by both requests issued by the local CPU and by other requests (using the address field) and responses (using the tag) observed from the bus
A request table entry is freed when a response to the request is observed on the bus in the acknowledgment cycle
The tag value associated with that request is reassigned by the bus arbiter only at this point, so there are no conflicts in the request tables
Request Processing
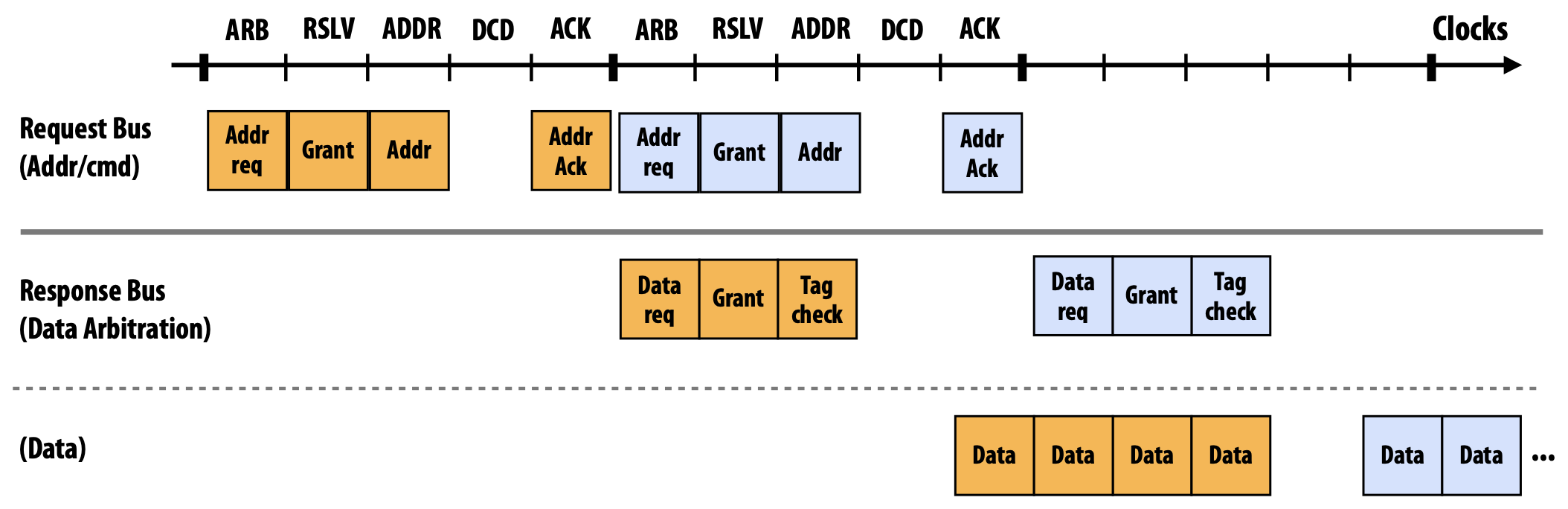
Request processing consists of a minimum of three phases:
- Address Request Phase
- Data Request Phase
- Data Transfer Phase
Three different memory operations can be in these three different phases at the same time
Address Request Phase
- Arbitration cycle: Cache controllers present requests for the address to the bus (many caches may be doing so in the same cycle)
- Resolution cycle: Address bus arbiter grants access to one of the requestors A request table entry is allocated for the request. Tag lines indicate the tag assigned to the request
- Address cycle: The bus “winner” places command/address on the bus
- Decode cycle: Caches perform snoop: look up tags, update cache state, etc. Write commits in this cycle
- Acknowledgement cycle: Caches acknowledge that this snoop result is ready. If a cache controller is not able to complete the snoop and take necessary actions, it can inhibit the completion phase using the inhibit-line
Data Request Phase and Data Transfer Phase
- Arbitration cycle: Responder presents intent to respond to the request with a tag (many caches or memory may be doing so in the same cycle)
- Resolution cycle: Address bus arbiter grants access to one of the responders
- Address cycle: The original requestor signals readiness to receive the response (or lack thereof: the requestor may be busy at this time)
- Acknowledgement cycle: The responder places response data on the data bus. Caches present the snoop result for the request with the data. The request table entry is freed
Reporting Snoop Results
The bus contains the same three OR-lines: shared line, dirty-line, inhibit-line (which extends the duration of the current response phase)
The snoop response is held in the request table from the time the snoop results are ready until the responder gains access to the bus
Flow Control
The cache has a data buffer for responses from the bus in addition to the write-back buffer to allow multiple transactions to be outstanding on the bus waiting for snoop and/or data responses from the controllers
Flow control is used to handle buffers filling up and is implemented using NACK (negative acknowledgment) lines on the bus
If a buffer is full when a request or response transaction is observed (which can be detected as soon as the transaction appears on the bus), the transaction is rejected and NACKed by memory or CPU
The transaction is then canceled everywhere and must be retried.
Conflict Resolution
The split-transaction bus presents an issue: a new request can appear on the bus before the snoop and/or servicing of an earlier request is complete. In particular, conflicting requests (two requests to the same memory block, at least one of which is a write) may be outstanding on the bus at the same time
It’s different from dealing with non-atomic state transitions: there, a conflicting request could be observed by a cache controller before its request even obtained the bus, so the request could be suitably modified before being placed on the bus. Here, both request sub-transactions have already appeared on the bus
The solution is to disallow transactions to the same block to be on a bus at the same time, so no conflicting requests may be outstanding on the bus at the same time
Since every controller has a record of the pending transactions that have been issued to the bus in its request table, no request is issued for a block that has a transaction outstanding
The request checks the currently pending entries in the request table:
- If it finds one with a matching address, it can take two possible courses of action:
- If the earlier request is a read for the same block, there is no conflict. No need to make a new bus request, just listen for the response to the earlier request on the bus
- If the earlier request is a write for the same block, there is a conflict. The CPU-side controller must hold on to the request until it sees a response to the previous request on the bus and only then attempt the request. It also may need to revise (convert) the next request as in non-atomic state transitions
- If it finds no matching address, it can issue the request to the bus:
- If it sees a conflicting request in the slot just before its own, it should issue a NOP request on the bus to occupy the slot it had been granted and withdraw from further arbitration until a response to the conflicting request has been generated. It also may need to revise (convert) the next request as in non-atomic state transitions
Serialization
Even though the bus is pipelined, the operations for an individual location are serialized as in the atomic case because only one request for a block can be outstanding on the bus at a time
Writes are committed during the address request phase, which affects the serialization
Multi-Level Cache with Split-Transaction Bus
To maintain high bandwidth while allowing controllers and caches to operate at their own rates, FIFO queues are placed between levels of hierarchy
Queues between the L2 cache and a bus also allow the cache controller to free the bus from incoming requests while issuing its own request, thus preventing fetch-deadlock
Deadlock
FIFO queues can cause a deadlock
For example, two coherence controllers are responding to each other’s requests, but the incoming queues are already full of other coherence requests. (1) Because queues are FIFO, the responses cannot pass the requests; (2) because the queues are full, each controller stalls trying to send a response; (3) because the queues are FIFO, the controller cannot switch to work on a subsequent request (or get to the response). Thus, the system deadlocks
One possible solution is to limit the number of outstanding requests from CPUs and then provide enough buffering for incoming requests and responses at each level
But it’s too costly and not scalable
The solution is:
- Use separate FIFO queues for responses and requests
- Cache must be able to service incoming requests while waiting to issue its own request as in the fetch deadlock problem
Responses don’t generate any further operations (so there is no circular dependency) and can be completed by the destination controller
Requests may generate a response, but no operation may generate another request.
Because a response cannot be blocked by another request (cache services respond even while waiting to send its own request), it will eventually be consumed by its destination controller, breaking the cyclic dependence
References
- Software Approach (1st ed). David Culler, Jaswinder Pal Singh, Anoop Gupta
- Computer Organization and Design RISC-V Edition The Hardware Software Interface (2nd ed). David A. Patterson, John L. Hennessy
- Cache inclusion policy - Wikipedia
- Snooping-Based Cache Coherence: CMU 15-418/618 Spring 2016
- Directory-Based Cache Coherence: CMU 15-418/618 Spring 2016
- A Basic Snooping-Based Multi-Processor Implementation: CMU 15-418/618 Spring 2016